Search is one of the most ubiquitous features: almost every application needs some form of search at some point.
Luckily, in the Rails realm, we have many established options that allow us to add the feature, from using a simple search scope with an ILIKE query to more complex options like pgsearch or even options like Elastic Search with the available adapters.
In this article, we will learn how to add intelligent search in Rails using the Typesense gem to show the power of Typesense as a search engine and the simplicity of its integration into Rails.
Let's start by understanding what Typesense is:
What is Typesense?
Typesense is a typo-tolerant search engine that's optimized for instant, typically under 50ms, search.
Initially, when we think about search in Rails applications, we think about a layer on top of our database that's able to search records that exist in our database using the query criteria provided by the user.
Ransack, the library Avo uses to handle search is a good example of this: it's built on top of Active Record and it can search and filter results in our database with some configuration.
On the other hand, an alternative like Typesense is more akin to Elastic Search or Algolia than it is to Ransack or PGSearch: we create an index with records from our database or external data and then we use Typesense to query that index which produces the results.
However, unlike Elastic Search, Typesense comes with sensible defaults for every config parameter which means it works out-of-the-box for most use cases.
The other advantage it has over database search is that it's very performant: it can handle many concurrent search queries per second while returning results fast.
Typesense concepts
The first concept to understand is that we interact with Typesense using a client which is, essentially, a wrapper around the calls we can make to the Typesense API that we can self-host or to the Typesense cloud API.
The following are useful concepts to know:
-
Document: In Typesense, a document is roughly equivalent to a table row. In the case of a movie application, an individual movie can be a document in Typesense. A thing to note is that documents don't have to map at all to our application data. For example, if we have a
Movieand aGenremodel, we could simply condense everything into a single document that represents the movie but also has information about the genre. - Collection: a collection is a group of related documents. A collection has to have a name and a description of the fields that will be indexed. An application can have many collections. However, we have to consider that as Typesense keeps data in memory, as we index more data, the memory needed to run Typesense increases.
-
Schema: it's the shape of the data we want to index for a given collection. It's basically a hash with a
nameattribute, afieldskey that contains the fields and types for each one of them and adefault_sorting_fieldattribute that we use to tell Typesense how to sort the documents for any given search term. - Node: a node is an instance of Typesense that contains a replica of the dataset. For production use cases, it's recommendable to run at least 3 nodes to tolerate node failure and avoid service disruption.
- Cluster: it's a group of nodes, used for high availability. When we deploy to Typesense Cloud, we can get a cluster configured out of the box. Otherwise, we need to set it up on our own.
What we will build
To show how Typesense works, we will build a simple Rails application able to list movies and we will add an instant search bar that allows us to search in our database.
Instead of using data from a gem like Faker, we will generate movie data using AI so the results are realistic.
The final result looks like the following:
Application Setup
The first thing we need to do is to install Typesense. We can do it using Docker or locally using Homebrew. For the sake of this tutorial let's use Homebrew:
brew install typesense/tap/typesense-server@29.0
brew services start typesense-server@29.0
After this, Typesense should be running at the port 8108 so we can test it with the following command:
curl http://localhost:8108/health
We should get {"ok":true} as a response which means the installation was successful and that we can integrate Typesense into our application.
The next step is to create our Rails application:
rails new typesense --css=tailwind --javascript=esbuild
I used AI to generate a dataset of 200 movies where each movie looks like this:
{
"id": "1",
"title": "The Shawshank Redemption",
"year": 1994,
"director": "Frank Darabont",
"rating": 9.3,
"runtime": 142,
"description": "Two imprisoned men bond over a number of years, finding solace and eventual redemption through acts of common decency."
},
To associate movies with their movie genres, we need a Movie a Genre and a MovieGenre models. Let's start by creating them, starting with the Movie model:
bin/rails generate model Movie title year:integer director rating:decimal runtime:integer description:text
Now, for the Genre model:
bin/rails generate model Genre name description:text
Lastly, the MovieGenre join model:
bin/rails generate model MovieGenre movie:references genre:references
Now for the models:
# app/models/movie.rb
class Movie < ApplicationRecord
validates :title, presence: true
has_many :movie_genres
has_many :genres, through: :movie_genres
end
# app/models/genre.rb
class Genre < ApplicationRecord
has_many :movie_genres
has_many :movies, through: :movie_genres
end
# app/models/movie_genre.rb
class MovieGenre < ApplicationRecord
belongs_to :movie
belongs_to :genre
end
Finally, we create a seed file where we can take the movie data generated with AI and have it in our database. If you want to use the same data as I did, feel free to download it from the application repository.
The seed file looks like this:
MovieGenre.destroy_all
Movie.destroy_all
Genre.destroy_all
genres_file = Rails.root.join('app', 'data', 'genres.json')
genres = JSON.parse(File.read(genres_file))
puts "Creating genres..."
genre_objects = {}
genres.each do |genre_data|
genre = Genre.create!(genre_data)
genre_objects[genre.name] = genre
puts "Created genre: #{genre.name}"
end
movies_file = Rails.root.join('app', 'data', 'movies.json')
movies_data = JSON.parse(File.read(movies_file))
puts "Creating movies..."
movies_data.each do |movie_data|
movie = Movie.create!(
title: movie_data['title'],
year: movie_data['year'],
director: movie_data['director'],
rating: movie_data['rating'],
runtime: movie_data['runtime'],
description: movie_data['description']
)
movie_data['genre'].each do |genre_name|
genre = genre_objects[genre_name]
if genre
MovieGenre.create!(movie: movie, genre: genre)
else
puts "Warning: Genre '#{genre_name}' not found for movie '#{movie.title}'"
end
end
puts "Created movie: #{movie.title} (#{movie.year})"
end
puts "Seed completed!"
puts "Created #{Genre.count} genres"
puts "Created #{Movie.count} movies"
puts "Created #{MovieGenre.count} movie-genre associations"
Finally, let's display the list of movies in the root view to make sure we have everything in place:
Now, we can start the Typesense integration:
Integrating Typesense
The first thing we need to do is install the Typesense Ruby gem:
bundle add typesense && bundle install
The next step is to configure the Typesense client using an initializer where we instantiate a new client defining a single host node and adding the default API key which is xyz
# config/initializers/typesense.rb
TYPESENSE_CLIENT = Typesense::Client.new(
nodes: [
{
host: ENV.fetch('TYPESENSE_HOST','localhost'),
port: ENV.fetch('TYPESENSE_PORT','8108'),
protocol: ENV.fetch('TYPESENSE_PROTOCOL','http')
}
],
api_key: ENV.fetch('TYPESENSE_API_KEY','xyz'),
log_level: :info,
connection_timeout_seconds: 2,
)
This provides us with access to a global TYPESENSE_CLIENT variable that we can use to interact with the API using the gem.
Now, the next thing we have to do is create a collection using the movie data we have in the database. We start by creating a Typesense model and add the create_schema class method to generate our desired schema:
class TypesenseService
def self.create_schema
TYPESENSE_CLIENT.collections.create(
name: "movies",
fields: [
{ name: 'movie_id', type: 'int32' },
{ name: 'title', type: 'string' },
{ name: 'year', type: 'int32' },
{ name: 'director', type: 'string' },
{ name: 'rating', type: 'float' },
{ name: 'runtime', type: 'int32' },
{ name: 'description', type: 'string' },
{ name: 'genres', type: 'string[]' },
],
default_sorting_field: 'movie_id'
)
end
def self.delete_schema
TYPESENSE_CLIENT.collections.delete(name: "movies")
end
end
This will create a movies collection with the schema we provided, containing all the fields we deem pertinent to search the collection later.
Indexing documents
The next step is to index every movie we have in our database, to achieve this, we will add an index_movies method to the service class that's in charge of adding each movie as a document to the movies collection:
class TypesenseService
def self.index_movies
Movie.all.each do |movie|
movie = serialize_movie(movie)
TYPESENSE_CLIENT.collections["movies"].documents.create(movie)
end
end
def self.index_movie(movie)
serialized_movie = serialize_movie(movie)
TYPESENSE_CLIENT.collections["movies"].documents.create(serialized_movie)
end
private
def self.serialize_movie(movie)
{
id: movie.id.to_s,
title: movie.title,
year: movie.year,
director: movie.director,
rating: movie.rating.to_f,
runtime: movie.runtime,
description: movie.description,
genres: movie.genre_list,
}
end
end
We have to make sure that every field matches the type we assigned to the collection when we created it. That's why we need to call .to_f on the rating and we have to add the genre_list method to the Movie class and make it return an array of strings that represent the movie's genres:
# app/models/movie.rb
class Movie < ApplicationRecord
# Rest of the code
def genre_list
genres.map(&:name)
end
end
Now, after we run TypesenseService.index_movies in the Rails console, we should be able to search records without issues:
Basic search
To perform a basic search with Typesense, we need to call the search method on the documents property for a given collection and pass a hash containing at least two keys: a q which is the search term and a query_by which represents the fields we want Typesense to query.
For example, let's say we want to search for movies with the term god in the title:
query_hash = {q: "god", query_by: "title"}
results = TYPESENSE_CLIENT.collections["movies"].documents.search(query_hash)
After calling this, the results variable is populated with a hash that contains the following keys:
- found: an integer that represents the amount of results that match with our query.
- hits: an array of hashes with the actual hits or matches.
- out_of: the total amount of documents in the collection we retrieved from.
- page: the current page that comes from Typesense pagination.
-
request_params: a hash that contains the params used to perform the request to Typesense's API. It includes the
collection_name, theqwhich is the query, thefirst_qwhich represents the first query in multi-query requests andper_pagewhich represents the amount of results that each page should contain. - searchtimems: the time it took to perform the search in milliseconds.
Currently, the hits array is what we need to give user feedback about the search result.
The hit hash has 5 keys but, for our immediate needs, we only need to work with 2 of them:
- document: the actual document with the shape we indexed it with.
-
highlights: a list of highlights that match our query term in the fields we're searching against. In our case, as we're only using the
titlefield it's a single match against the wordgodin thetitle.
An actual result with real data looks like this:
{"document"=>
{"description"=>"In the slums of Rio, two kids' paths diverge as one struggles to become a photographer and the other a kingpin.",
"director"=>"Fernando Meirelles",
"genres"=>["Crime", "Drama"],
"id"=>"31",
"movie_id"=>30,
"rating"=>8.5,
"runtime"=>130,
"title"=>"City of God",
"year"=>2002},
"highlight"=>{"title"=>{"matched_tokens"=>["God"], "snippet"=>"City of <mark>God</mark>"}},
"highlights"=>[{"field"=>"title", "matched_tokens"=>["God"], "snippet"=>"City of <mark>God</mark>"}],
"text_match"=>578730123365187705,
"text_match_info"=>
{"best_field_score"=>"1108091338752", "best_field_weight"=>15, "fields_matched"=>1, "num_tokens_dropped"=>0, "score"=>"578730123365187705", "tokens_matched"=>1, "typo_prefix_score"=>0}
}
We now understand how basic search works out of the box but let's learn how to integrate it into our application:
Integrating search
The first step is to define a route and a controller we can use to perform our search. Let's start with the route:
# config/routes.rb
Rails.application.routes.draw do
# Rest of the routes
get "search", to: "search#index"
end
In theory, we could define a MoviesController and handle search conditionally in the index method but, as the partial or JSON view we might end up using for search might differ from a regular movie, let's keep it separate in a SearchController:
# app/controllers/search_controller.rb
class SearchController < ApplicationController
def index
@movies = []
query = params[:query]
if query.present?
results = TYPESENSE_CLIENT.collections["movies"].documents.search(
q: query,
query_by: "title,description",
page: params[:page] || 1,
per_page: params[:per_page] || 10
)
@movies = results["hits"].map do |hit|
{
title: hit["document"]["title"],
year: hit["document"]["year"],
director: hit["document"]["director"],
rating: hit["document"]["rating"],
runtime: hit["document"]["runtime"],
description: hit["document"]["description"],
genres: hit["document"]["genres"]
}
end
end
respond_to do |format|
format.html
format.json { render json: @movies.to_json, status: :ok }
end
end
end
The process here is divided into three parts:
-
The search: we're doing something similar to what we already did before by performing a search with the query present in the params looking in the
titleanddescriptionof the documents. - Serializing: we serialize the results by reading from every search “hit” and transforming that into a Ruby hash that we use in the view.
- Controller response: we respond to HTML and JSON responses.
After adding a basic form:
<div class="max-w-screen-lg mx-auto pt-6 pb-16">
<div class="mb-6">
<%= form_with url: search_index_path, method: :get, local: false do |form| %>
<%= form.text_field :query,
placeholder: "Search movies...",
class: "w-full px-4 py-2 border border-gray-300 rounded-full focus:ring-2 focus:ring-blue-500 focus:border-blue-500 outline-none",
value: params[:query]
%>
<% end %>
</div>
<div class="w-full">
<%= render "search/results", results: @movies || [] %>
</div>
</div>
And a results partial:
<% if results.empty? %>
<div class="py-8 text-center">
<div class="text-gray-400 text-6xl mb-4">🔍</div>
<p class="text-gray-500 text-lg">No movies found</p>
<p class="text-gray-400 text-sm mt-2">Try searching for a different title or keyword</p>
</div>
<% else %>
<div>
<div class="text-sm text-gray-600">
Found <%= results.length %> movie<%= 's' if results.length != 1 %>
</div>
<ul class="divide-y divide-gray-200">
<% results.each do |movie| %>
<li class="bg-white py-4">
<div class="flex justify-between items-start">
<h2 class="font-bold text-gray-900"><%= movie[:title] %></h2>
<span class="text-blue-900 text-sm font-medium">
<%= movie[:year] %>
</span>
</div>
<div class="mt-1 mb-3">
<p class="text-gray-600 text-sm leading-relaxed"><%= movie[:description] %></p>
</div>
<% if movie[:genres] && movie[:genres].any? %>
<div class="mt-3 flex flex-wrap gap-2">
<% movie[:genres].each do |genre| %>
<span class="bg-gray-100 text-gray-700 text-xs px-2 py-1 rounded-full">
<%= genre %>
</span>
<% end %>
</div>
<% end %>
</li>
<% end %>
</ul>
</div>
<% end %>
This produces the following result:
We now have a working search integration with Rails but we can do better: let's add the ability to highlight search results:
Highlighting results
Typesense gives us the ability to highlight results out of the box by accessing the pre-formatted snippet attribute on the highlights attribute for a hit.
Let's start by adding a highlight attribute to our result hash:
class SearchController < ApplicationController
def index
# Rest of the code
if query.present?
# Code to fetch results
@movies = results["hits"].map do |hit|
{
title: hit["document"]["title"],
year: hit["document"]["year"],
director: hit["document"]["director"],
rating: hit["document"]["rating"],
runtime: hit["document"]["runtime"],
description: hit["document"]["description"],
genres: hit["document"]["genres"],
highlight: hit["highlight"],
}
end
end
# Response cod
end
end
If we then access the result[:highlight] property, we will get a hash that looks like the following:
"description"=>{"matched_tokens"=>["Lebowski"], "snippet"=>"Ultimate LA slacker Jeff \"The Dude\" <mark>Lebowski</mark>, mistaken for a millionaire of the same name, seeks restitution for a rug ruined by debt collectors."}, "title"=>{"matched_tokens"=>["Lebowski"], "snippet"=>"The Big <mark>Lebowski</mark>"}}
Here, we get a match for the term Lebowski on the title and the description fields so that's why the hash has two keys corresponding to each field.
However, we don't have the guarantee that a match will happen against the title and the description so we need to keep that in mind.
When it comes to displaying the highlighted text, we can use the snippet attribute as it gives us the HTML we can use directly.
So let's modify our title:
# Accessing the snippet for the title or the title itself
<h2 class="font-bold text-gray-900"><%= sanitize movie[:highlight].fetch("title", {}).fetch("snippet", movie[:title]) %></h2>
And doing the same for the description:
<p class="text-gray-600 text-sm leading-relaxed"><%= sanitize movie[:highlight].fetch("description", {}).fetch("snippet", movie[:description]) %></p>
You might notice that, even if not overly complex, we introduced some logic into our result view so let's extract this into a helper:
# app/helpers/search_helper.rb
module SearchHelper
def highlighted_field(result, field)
result[:highlight].fetch(field, {}).fetch("snippet", result[field.to_sym])
end
end
This produces the following result:
Keeping data in sync
We learned how to create a collection and index documents into it. This is handy but our data would hardly be static so let's add methods to add, remove and update individual records to our movies collection.
class TypesenseService
# Rest of the code
def self.update_movie(id, fields)
TYPESENSE_CLIENT.collections["movies"].documents[id.to_s].update(fields)
end
def self.upsert_movie(movie)
serialized_movie = serialize_movie(movie)
TYPESENSE_CLIENT.collections["movies"].documents.upsert(serialized_movie)
end
def self.delete_movie(movie)
TYPESENSE_CLIENT.collections["movies"].documents[movie.id.to_s].delete
end
private
def self.serialize_movie(movie)
{
id: movie.id.to_s,
title: movie.title,
year: movie.year,
director: movie.director,
rating: movie.rating.to_f,
runtime: movie.runtime,
description: movie.description,
genres: movie.genre_list,
}
end
end
Now, let's create a new movie and test that our method to index individual movies is working:
movie = Movie.create!(
title: "Moonlight",
year: 2016,
director: "Barry Jenkins",
rating: 7.4,
runtime: 111,
description: "A young African-American man grapples with his identity and sexuality while experiencing the everyday struggles of childhood, adolescence, and burgeoning adulthood."
)
TypesenseService.index_movie(movie)
Now, if we search for the movie, we should get a result back:
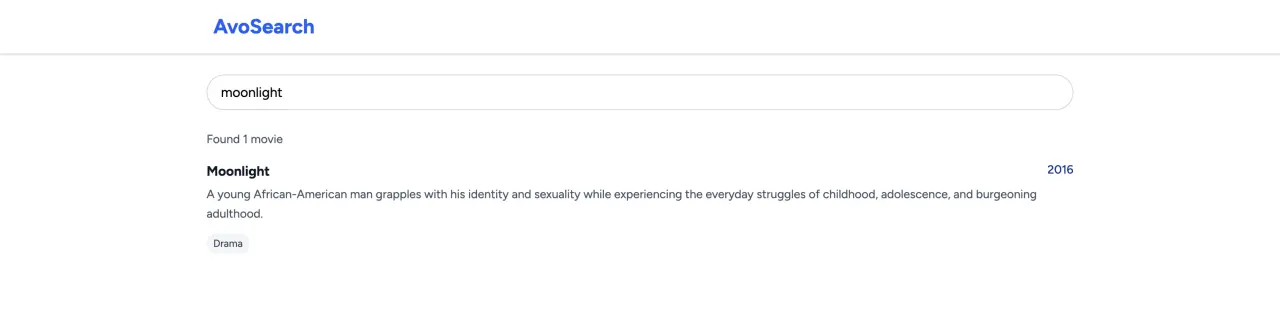
To test updating (changing some fields) or upserting (creating or updating a movie) let's change the name to Moonlight Sonata in the console and update the document:
movie = Movie.find_by(title: "Moonlight")
movie.update(title: "Moonlight Sonata")
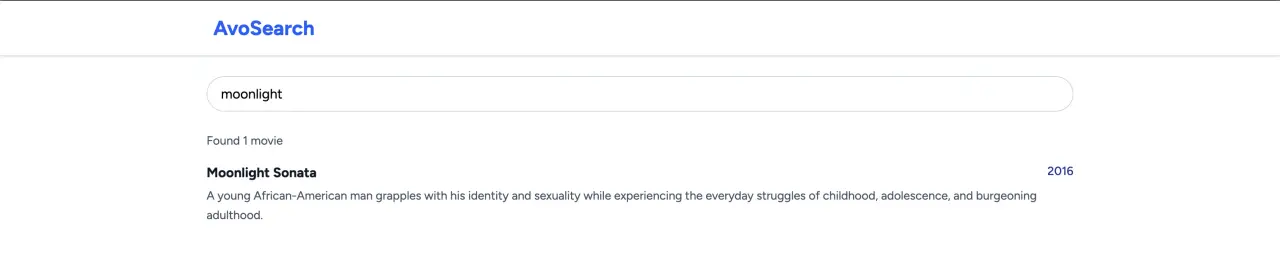
If we perform the search now, the result should be the same which means we have to update the index:
TypesenseService.update_movie(movie.id, title: movie.title)
Now, if we search the term moonlight we should get the updated version returned:
We can also use the upsert method and pass the movie instance:
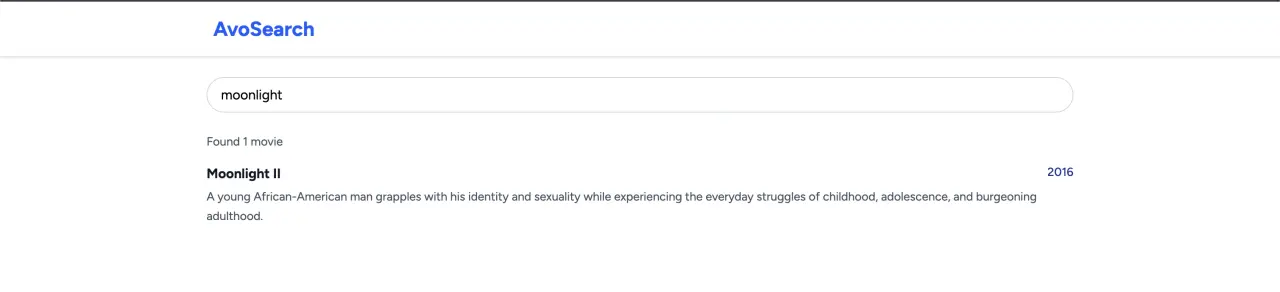
movie.update(title: "Moonlight II")
TypesenseService.upsert_movie(movie)
Which should update the index correctly:
If we need to delete a movie from the index we can do it with the delete_movie method:
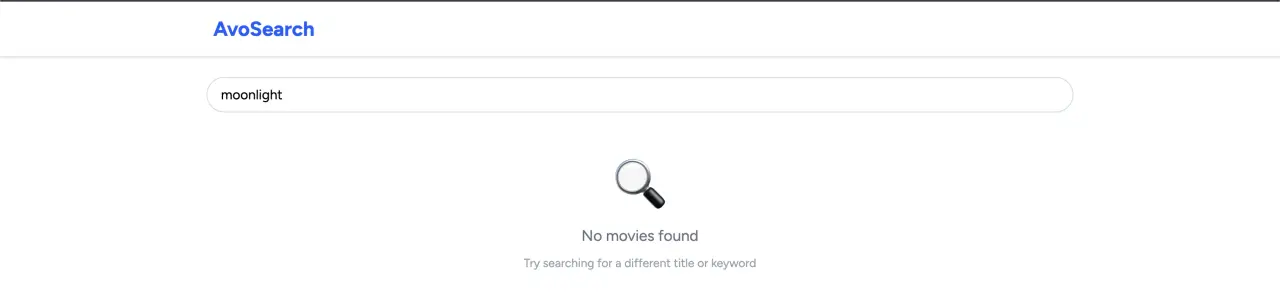
TypesenseService.delete_movie(movie)
We then search for the same term and we should get no results:
With this in place, let's add the appropriate methods to callbacks so our index is updated when we perform CRUD operations:
Callbacks
To keep things in sync, we should make sure we're adding new movies to the index, updating the index when a movie is updated and removing it from the index when it's deleted.
The following code does the trick:
class Movie < ApplicationRecord
# Rest of the code
after_create_commit :index_movie do
TypesenseService.index_movie(self)
end
after_update_commit :update_movie do
TypesenseService.update_movie(self.id, self.attributes)
end
after_destroy_commit :delete_movie do
TypesenseService.delete_movie(self)
end
end
Let's add a new movie to test that everything is working:
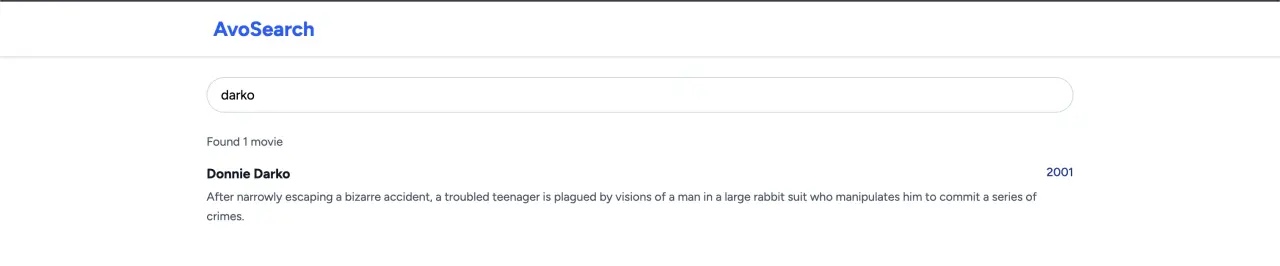
movie = Movie.create!(
title: "Donnie Darko",
year: 2001,
director: "Richard Kelly",
rating: 8.0,
runtime: 113,
description: "After narrowly escaping a bizarre accident, a troubled teenager is plagued by visions of a man in a large rabbit suit who manipulates him to commit a series of
crimes."
)
Now, if we search for the movie we should get the result without manually adding the document to the index.
Up to this point, we have a working search feature with Rails but you might be thinking: the TypesenseService class is pretty tied to the Movie model and that accessing the TYPESENSE_CLIENT in the controller is a bit verbose and unnecessary.
We could improve that by making the service class more abstract and adding a searchable callback to add a search method to any model that includes it.
However, to achieve this, we will use the typesense-rails gem which helps us handle everything for us:
Using the typesense-rails gem
This gem is a fork of the algolia-rails gem, adapted to work with Typesense while keeping similar functionality and API.
Some of the features it has are:
- Automatic indexing with callbacks.
- It supports multiple pagination backends like Pagy, Kaminari and WillPaginate.
- Support for faceted search.
- Support for nested associations.
- Attribute customization and serialization.
- Support for multiple and single way synonyms.
Please note that at the time of writing this, the gem doesn't have a final release and its current version is 1.0.0.rc1.
Let's start by removing typesense-ruby and installing typesense-rails:
# Gemfile
gem 'typesense-rails', '~> 1.0.0.rc1'
bundle install
As typesense-ruby is a dependency of the gem, our search feature should still be working but let's start by changing the initializer:
# config/initializers/typesense.rb
Typesense.configuration = {
nodes: [{
host: ENV.fetch('TYPESENSE_HOST','localhost'),
port: ENV.fetch('TYPESENSE_PORT','8108'),
protocol: ENV.fetch('TYPESENSE_PROTOCOL','http')
}],
api_key: ENV.fetch('TYPESENSE_API_KEY','xyz'),
connection_timeout_seconds: 2,
log_level: :info
}
To start configuring it, let's remove the callbacks, include the Typesense module and define its configuration within the model:
# app/models/movie.rb
class Movie < ApplicationRecord
include Typesense
# Validations and associations
typesense do
attributes :title, :description, :year
# Dynamic attribute
attribute :genres do
genres.map(&:name)
end
default_sorting_field :rating
predefined_fields [
{name: 'title', type: 'string'},
{name: 'description', type: 'string'},
{name: 'year', type: 'int32'},
{name: 'genres', type: 'string[]'}
]
end
end
end
We're configuring the same things we configured before but within the model instead of using a service class.
Now, to test that everything's working, let's delete the movies collection and index it using the reindex method that comes with typesense-rails:
TypesenseService.delete_schema
Movie.reindex
The gem defines a search method that we can use to replace what we have in the controller while achieving the same result.
It receives the query, the fields that we want to search against and any extra search params for things like pagination or faceted search.
An example of its use:
Movie.search("lebowski", "title,description", {page: params[:page], per_page: 2})
Which produces the following:
# =>
[#<Movie:0x000000012aa5b060
id: 121,
title: "The Big Lebowski",
year: 1998,
director: "Joel Coen",
rating: 0.79e1,
runtime: 117,
description: "Ultimate LA slacker Jeff \"The Dude\" Lebowski, mist...",
created_at: "2025-10-05 00:14:50.184423000 +0000",
updated_at: "2025-10-05 00:14:50.184423000 +0000">]
As you can see, it returns an instance of a Movie instead of an array of hits so we don't actually have to map that to a hash like we did before.
This means that we can have the following code in the controller:
class SearchController < ApplicationController
def index
query = params[:query] || ""
@movies = []
if query.present?
@movies = Movie.search(query, "title, description", {
page: params[:page] || 1,
per_page: params[:per_page] || 2
})
end
respond_to do |format|
format.html
format.json { render json: @movies.to_json, status: :ok }
end
end
end
This produces the same result as before but with a much simpler code surface:
Now that we have everything working as before, let's add pagination using the Pagy gem:
Pagination
Luckily for us, the typesense-rails gem comes with built-in support for pagination.
Let's start by installing Pagy:
bundle add pagy && bundle install
The next step is to define the pagination engine in our Typesense initializer:
# config/initializers/typesense.rb
Typesense.configuration = {
# Rest of the config
pagination_backend: :pagy
}
Then, we require the Pagy backend module in our application controller:
class ApplicationController < ActionController::Base
include Pagy::Backend
end
And the Pagy frontend module in the application helper:
module ApplicationHelper
include Pagy::Frontend
end
The next step is to define the @pagy variable in the controller:
class SearchController < ApplicationController
def index
@pagy, @movies = Movie.search(params[:query], "title, description", {
per_page: params[:per_page] || 2,
page: params[:page] || 1
})
respond_to do |format|
format.html
format.json { render json: @movies.to_json, status: :ok }
end
end
end
Then, we render the pagination component provided by Pagy if there is more than 1 page in the results:
<div class="w-full">
<%= render "search/results", results: @movies %>
<%== pagy_nav(@pagy) if @pagy.pages > 1 %>
</div>
And adding the Pagy CSS for Tailwind:
/* app/assets/stylesheets/application.tailwind.css */
@import "tailwindcss";
.pagy {
@apply flex space-x-1 font-semibold text-sm text-gray-500;
a:not(.gap) {
@apply block rounded-lg px-3 py-1 bg-gray-200;
&:hover {
@apply bg-gray-300;
}
&:not([href]) { /* disabled links */
@apply text-gray-300 bg-gray-100 cursor-default;
}
&.current {
@apply text-white bg-gray-400;
}
}
label {
@apply inline-block whitespace-nowrap bg-gray-200 rounded-lg px-3 py-0.5;
input {
@apply bg-gray-100 border-none rounded-md;
}
}
}
We then get pagination without having to do any extra work:
Sorting
We can determine the way results are sorted using the sort_by attribute and passing the field and the sorting criteria.
Let's add the ability to sort by the year of the movie in descending order.
@pagy, @movies = Movie.search(params[:query], "title, description", {
per_page: params[:per_page] || 2,
page: params[:page] || 1,
sort_by: "year:desc"
})
As you can imagine, this query sorts the results by the year a given movie was published in descending order:
We can modify this to show movies in ascending order by year with sort_by: 'year:asc' and we can also make this configurable as long as it's useful for our users.
Summary
Search is a requirement for most web and native applications nowadays. But not every approach to search is created equal: some of them are more “intelligent” than others.
For example, database-backed search using solutions like Ransack or pg_search are excellent choices for simple search, which should cover most applications, especially when starting out.
Solutions like Typesense, Meilisearch, Elastic Search are nice options as they allow us to detach search from the database and move it into an index that's more performant, redundant and can be fine tuned to achieve fast and sensible results.
In this article we showcased how to integrate Typesense into a Rails application by using the typesense-ruby gem which is a wrapper around the Typesense API.
Typesense uses a separate index of collections which are a list of related documents that we can query with different degrees of granularity.
The service offers simple, intelligent search by default and has a lot of nice and advanced features we can use to help our users find what they're looking for more efficiently.
We learned how to integrate Typesense, how to perform instant search with highlighting, how to keep data in sync between our application's records and the Typesense index and how to add advanced search features like typo tolerance or vector search.
All in all, Typesense is a very convenient service that we can self-host or use their paid cloud service if it makes sense for our business while also having the peace of knowing the library is open source.
I hope this article helps you integrate intelligent search with Typesense in your next Rails application.
Have a good one and happy coding!